Robust Visual Embodiment: How Robots Discover Their Bodies in Real Environments
Robin Chhabra, Ammar J Mahmood, Salim Rezvani
Toronto Metropolitan University (Formerly Ryerson)
ArXiv | Appendix
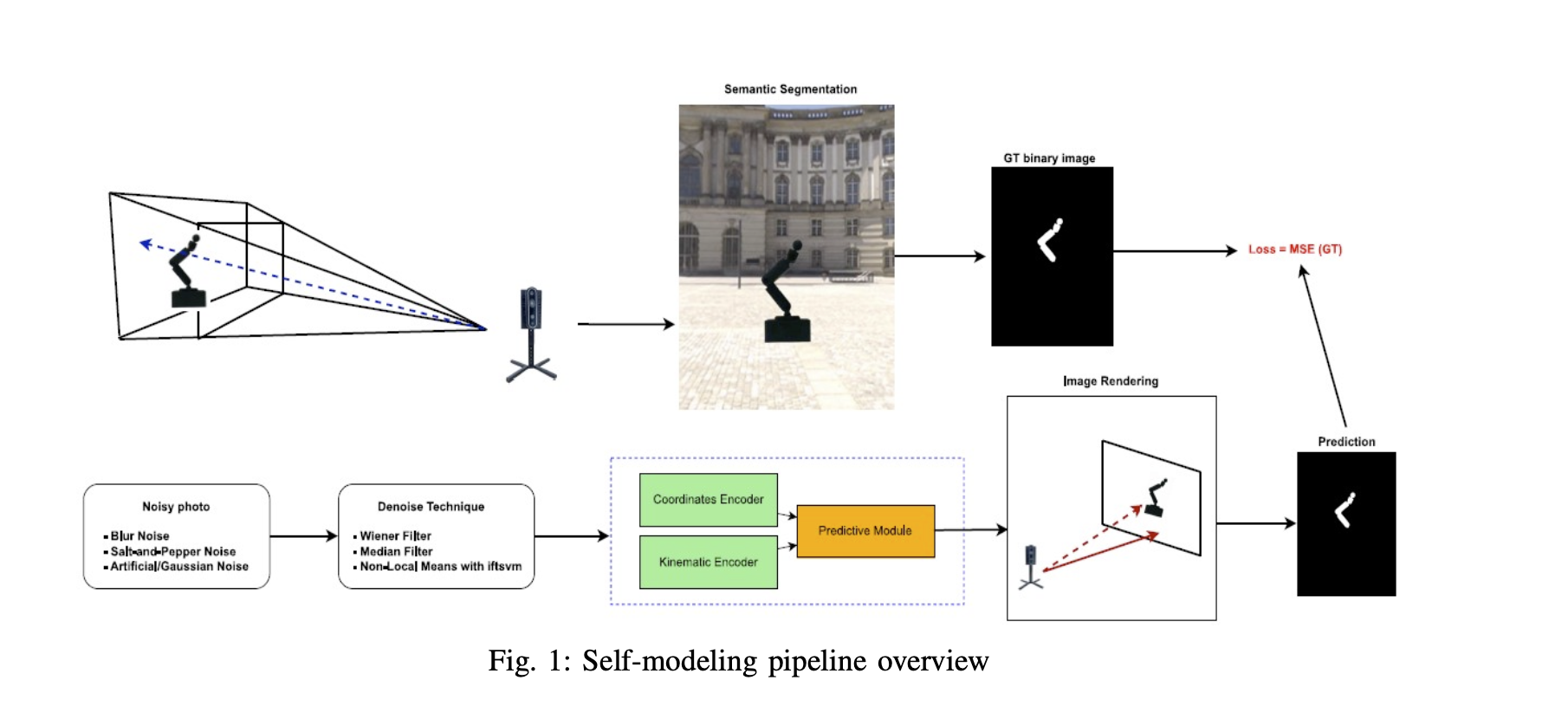 Robots with internal visual self-models promise unprecedented adaptability, yet existing autonomous modeling
pipelines remain fragile under realistic sensing conditions such as noisy imagery and cluttered backgrounds. This
paper presents the first systematic study quantifying how visual degradations—including blur, salt-and-pepper
noise, and Gaussian noise—affect robotic self-modeling. Through both simulation and physical experiments, we
demonstrate their impact on morphology prediction, trajectory planning, and damage recovery in state-of-the-art
pipelines. To overcome these challenges, we introduce a task-aware denoising framework that couples classical
restoration with morphology-preserving constraints, ensuring retention of structural cues critical for
self-modeling. In addition, we integrate semantic segmentation to robustly isolate robots from cluttered and
colorful scenes. Extensive experiments show that our approach restores near-baseline performance across simulated
and physical platforms, while existing pipelines degrade significantly. These contributions advance the robustness
of visual self-modeling and establish practical foundations for deploying self-aware robots in unpredictable
real-world environments.
Robots with internal visual self-models promise unprecedented adaptability, yet existing autonomous modeling
pipelines remain fragile under realistic sensing conditions such as noisy imagery and cluttered backgrounds. This
paper presents the first systematic study quantifying how visual degradations—including blur, salt-and-pepper
noise, and Gaussian noise—affect robotic self-modeling. Through both simulation and physical experiments, we
demonstrate their impact on morphology prediction, trajectory planning, and damage recovery in state-of-the-art
pipelines. To overcome these challenges, we introduce a task-aware denoising framework that couples classical
restoration with morphology-preserving constraints, ensuring retention of structural cues critical for
self-modeling. In addition, we integrate semantic segmentation to robustly isolate robots from cluttered and
colorful scenes. Extensive experiments show that our approach restores near-baseline performance across simulated
and physical platforms, while existing pipelines degrade significantly. These contributions advance the robustness
of visual self-modeling and establish practical foundations for deploying self-aware robots in unpredictable
real-world environments.
Visual Noise Impact on Self-Modeling
We evaluate the impact of three representative noise types on robotic self-modeling:
- Gaussian Blur: Reduces edge sharpness and fine structures, often caused by camera motion or lens imperfections.
- Salt-and-Pepper Noise: Introduces random extreme pixel values from sensor faults or dust, disrupting color-based segmentation.
- Gaussian Noise: Simulates common real-world sensor perturbations like electronic interference or low-light variability.
Method Overview

Our task-aware denoising pipeline operates in three steps: 1) Semantic segmentation to isolate the robot from cluttered backgrounds, 2) Integration with self-modeling using the Free-Form Kinematic Self-Model (FFKSM) framework, and 3) Noise-specific filtering using Wiener filtering for blur, median filtering for salt-and-pepper noise, and Non-Local Means with IFT-SVM for Gaussian noise. This ordering ensures that the robot is first separated from the background and correctly modeled before denoising restores corrupted inputs.
Semantic Segmentation Results
 Semantic Segmentation Comparison
Semantic Segmentation Comparison
FFKSM vs Our Method across different cluttered backgrounds
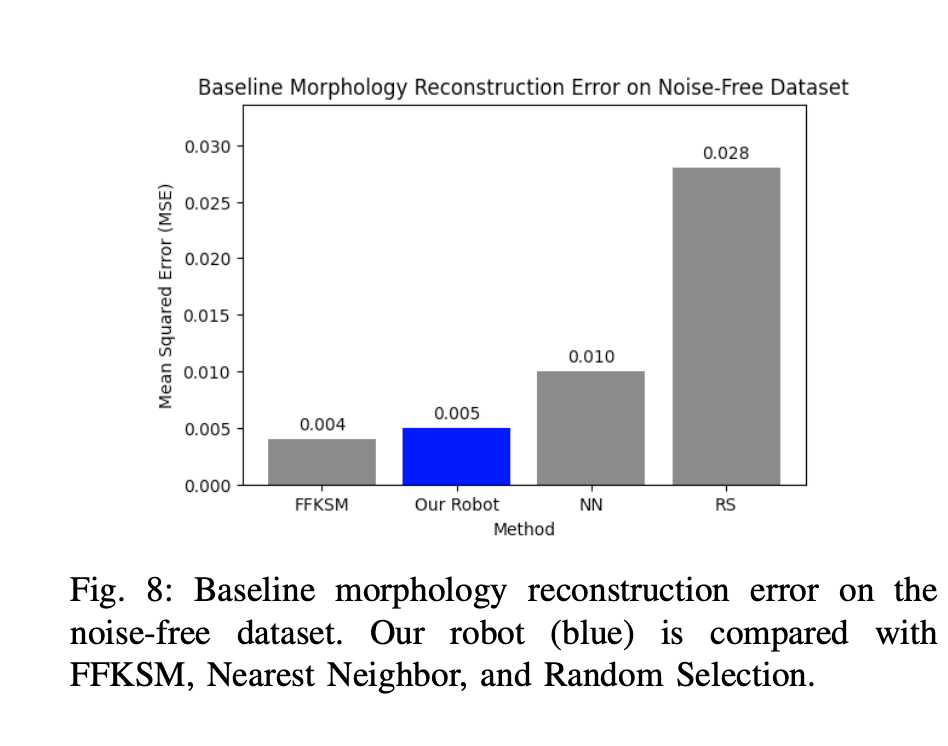 Baseline Performance
Baseline Performance
Morphology reconstruction error on noise-free dataset
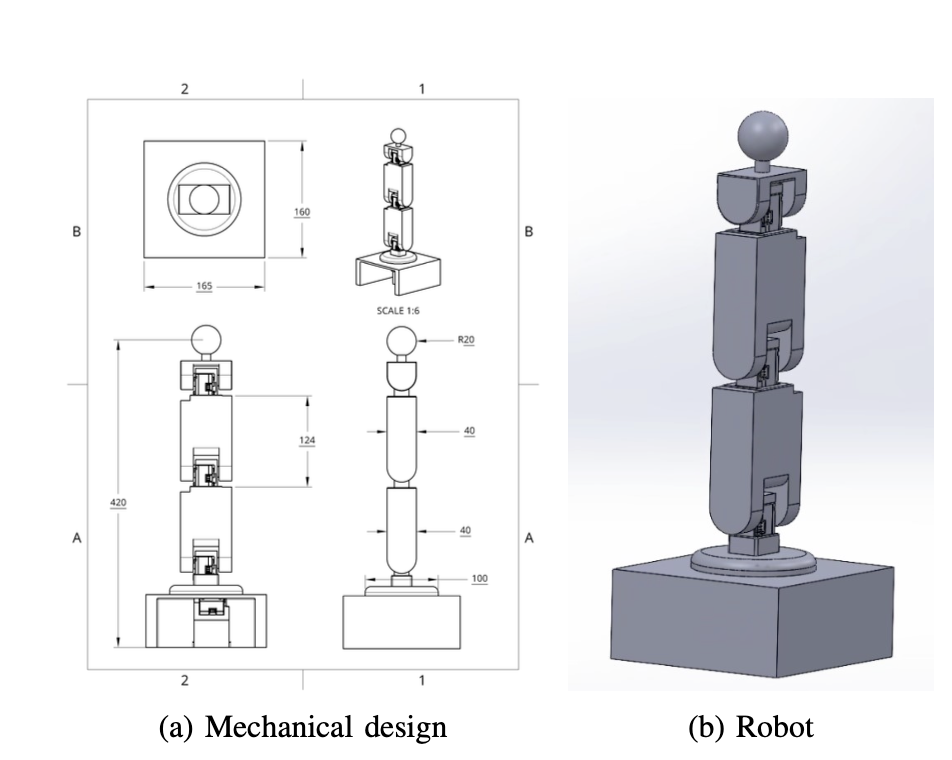
Physical Robot Experiments
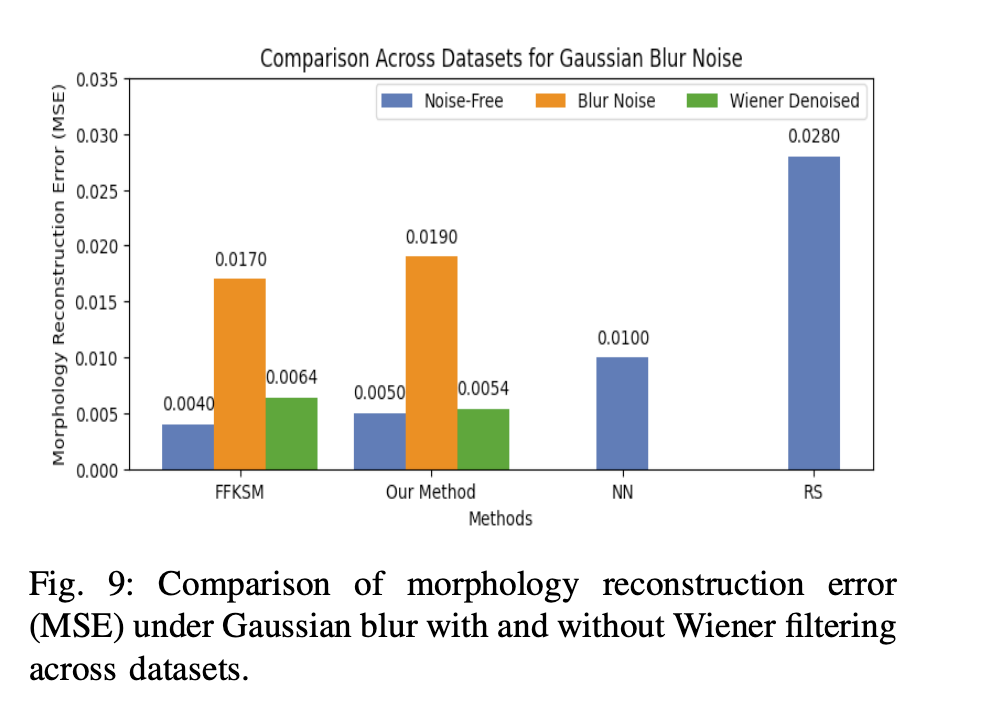
Morphology reconstruction error under Gaussian blur with and without Wiener filtering
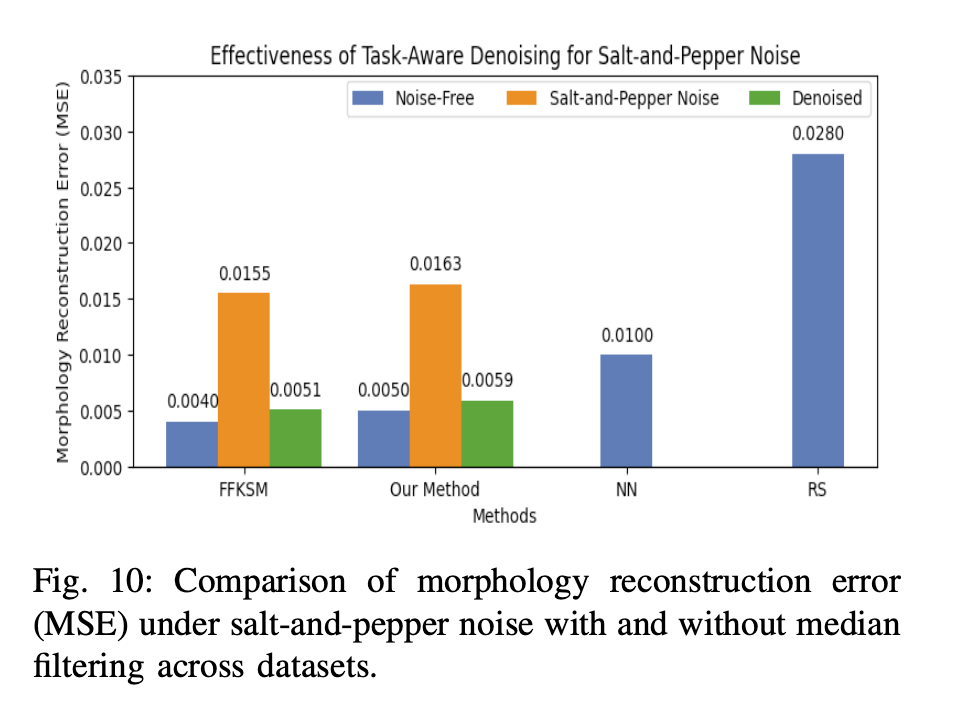
Morphology reconstruction error under salt-and-pepper noise with and without median filtering
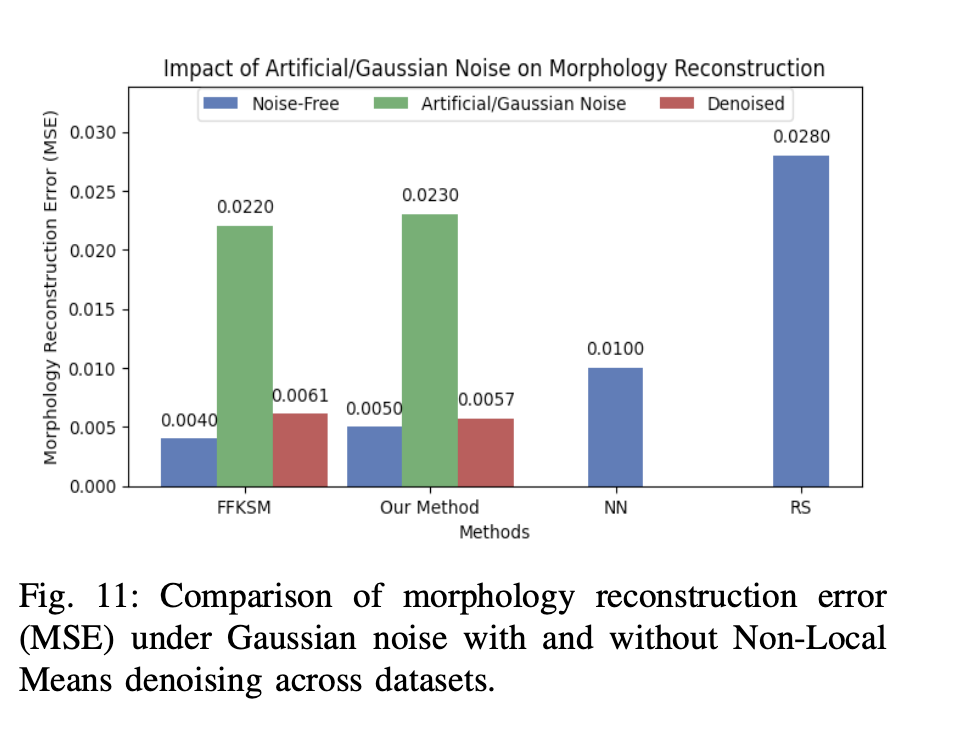
Morphology reconstruction error under Gaussian noise with and without Non-Local Means denoising
Technical Details
Hardware and Software
- 4-DOF robotic manipulator with 3D-printed PLA components
- Dynamixel XL330-M288 servos
- Intel RealSense D435 RGB-D camera
- Ubuntu Linux, Python implementation
- Free-Form Kinematic Self-Model (FFKSM) framework
Denoising Techniques
- Wiener filtering for blur removal
- Median filtering for salt-and-pepper noise
- Non-Local Means with IFT-SVM for Gaussian noise
- Semantic segmentation for cluttered backgrounds
- Task-aware morphology preservation constraints
Results Summary
Our experimental results demonstrate three key findings:
- Visual noise significantly impairs morphology reconstruction - MSE values rise three- to fivefold under noise conditions
- Task-aware denoising restores near-baseline performance - Our method achieves MSE of 0.0054-0.0059 compared to FFKSM's 0.0061-0.0064
- Semantic segmentation enables real-world deployment - Up to 4× improvement in IoU and 3× improvement in F1-score over color-based segmentation
BibTeX
@article{robust_visual_embodiment2025,
title={Robust Visual Embodiment: How Robots Discover Their Bodies in Real Environments},
author={Robin Chhabra and Ammar J Mahmood and Salim Rezvani},
journal={Conference/Journal Name},
year={2025}
}
Contact
Please reach out to ammar.j.mahmood@torontomu.ca or robin.chhabra@torontomu.ca for questions about this research.